Active Learning
Created: 05 Jan 2023, 02:20 PM | Modified: =dateformat(this.file.mtime,"dd MMM yyyy, hh:mm a")
Tags: knowledge, GeneralDL
Active Learning in Machine Learning | by Ana Solaguren-Beascoa, PhD | Towards Data Science
Active learning is the name used for the process of prioritising the data which needs to be labelled in order to have the highest impact to training a supervised model.
The steps to use active learning on an unlabelled data set are:
- A very small subsample of this data needs to be manually labelled.
- Model needs to be trained on the small amount of labelled data. a. The model is of course not going to be great but will help us get some insight on which areas of the parameter space need to be labelled first to improve it.
- After the model is trained, the model is used to predict the class of each remaining unlabelled data point.
- A score is chosen on each unlabelled data point based on the prediction of the model.
- Once the best approach has been chosen to prioritise the labelling, this process can be iteratively repeated: a. a new model can be trained on a new labelled data set, which has been labelled based on the priority score. b. Once the new model has been trained on the subset of data, the unlabelled data points can be ran through the model to update the prioritisation scores to continue labelling.
In this way, one can keep optimising the labelling strategy as the models become better and better.
From <https://towardsdatascience.com/active-learning-in-machine-learning-525e61be16e5>
Papers, Articles
Specific papers
- Bayesian Active Learning by Disagreement Article 1, Article 2 Original paper: Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classification and preference learning. arXiv preprint arXiv:1112.5745, 2011. Recent paper: Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In International Conference on Machine Learning, pages 1183–1192. PMLR, 2017. Key feature: In a Bayesian neural network, every parameter in the model is sampled from a distribution. Then, when doing inference, we need to integrate over all the possible parameters. So we’re using an ensemble of infinite different networks to compute the output. … It’s intractable to integrate over all possible parameter values in the distribution, so instead Monte Carlo integration can be used.
- Not All Labels Are Equal - Rationalizing The Labeling Costs for Training Object Detection
- Recently, several methods have been adapted specifically for the task of object detection [6,7,22–25], some of which are based on the core-set approaches where the diversity of the training examples is taken into account. However, the state-of-the-art approaches are based on the uncertainty [4, 5, 8, 26].
- The work of [26] consists of an ensemble of object detectors that provide bounding boxes and probabilities for each class of interest. Then, a scoring function is used to obtain a single value representing the informativeness of each unlabeled image.
- Similar to that is the work of [8] where the authors compute the instance-based uncertainty.
- Another work [4] gives an elegant solution, reaching promising results compared with other single-model methods. The authors train a network in the task of detection while learning to predict the final loss. In the sample acquisition stage, samples with the highest prediction loss are considered the most interesting ones and are chosen to be labeled.
- In the state-of-the-art approach [5], authors define the Aleatoric and Epistemic uncertainty, in both class and bounding box level, and use the combined score to determine the images that need labeling.
- Our work is related but different from the above-mentioned works. Similarly, we consider the uncertainty of the detector as part of the solution. Unlike them, we find that the robustness of the detector is even more reliable as an acquisition function, especially for the low-performing classes. We then unify these two scores to reach high performance in the majority of classes. [4] Donggeun Yoo and In So Kweon. Learning loss for active learning. In CVPR, 2019. 1, 2, 5 [5] Jiwoong Choi, Ismail Elezi, Hyuk-Jae Lee, Clement Farabet, and Jose M. Alvarez. Active learning for deep object detection via probabilistic modeling. In ICCV, 2021. 1, 2, 5 [8] Tianning Yuan, Fang Wan, Mengying Fu, Jianzhuang Liu, Songcen Xu, Xiangyang Ji, and Qixiang Ye. Multiple instance active learning for object detection. In CVPR, 2021. 2, 5 [26] Elmar Haussmann, Michele Fenzi, Kashyap Chitta, Jan Ivanecky, Hanson Xu, Donna Roy, Akshita Mittel, Nicolas Koumchatzky, Clement Farabet, and Jose M Alvarez. Scalable active learning for object detection. In IV, 2020. 2
Overview articles, Survey papers
A Comparative Survey of Deep Active Learning
Learning with not Enough Data Part 2: Active Learning | Lil’Log
What is Active Learning?
- When you don’t have enough labeled data and it’s expensive and/or time consuming to label new data, active learning is the solution. Active learning is a semi-supervised ML training paradigm which, like all semi-supervised learning techniques, relies on the usage of partially labeled data. Active Learning helps to select unlabeled samples to label that will be most beneficial for the model, when retrained with the new sample.
- Active learning is a semi-supervised ML training paradigm which, like all semi-supervised learning techniques, relies on the usage of partially labeled data.
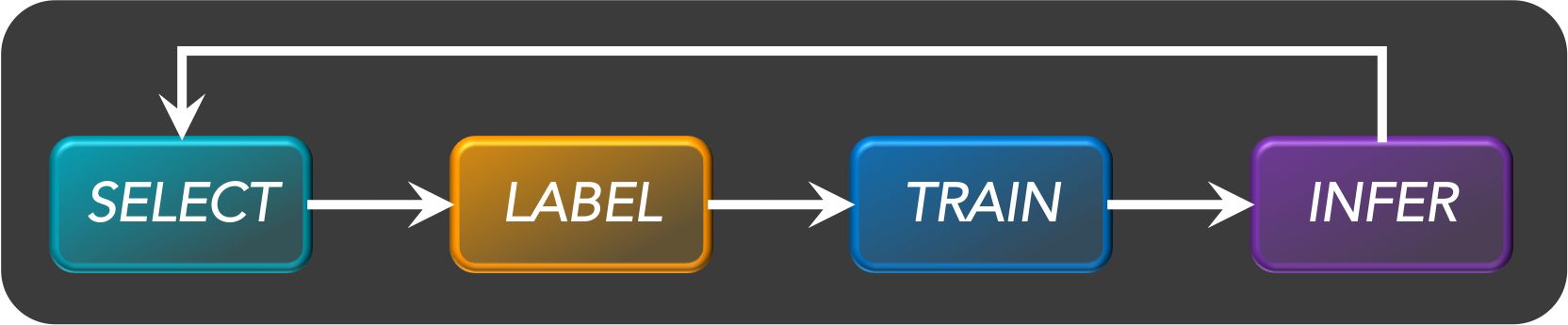
- Active Learning consists of dynamically selecting the most relevant data by sequentially:
- selecting a sample of the raw (unannotated) dataset (the algorithm used for that selection step is called a querying strategy).
- getting the selected data annotated.
- training the model with that sample of annotated training data.
- running inference on the remaining (unannotated) data.
- That last step is used to evaluate which records should be then selected for the next iteration (called a loop). However, since there is no ground truth for the data used in the inference step, one cannot simply decide to feed the – data where the model failed to make the correct prediction, and has instead to use metadata (such as the confidence level of the prediction) to make that decision.
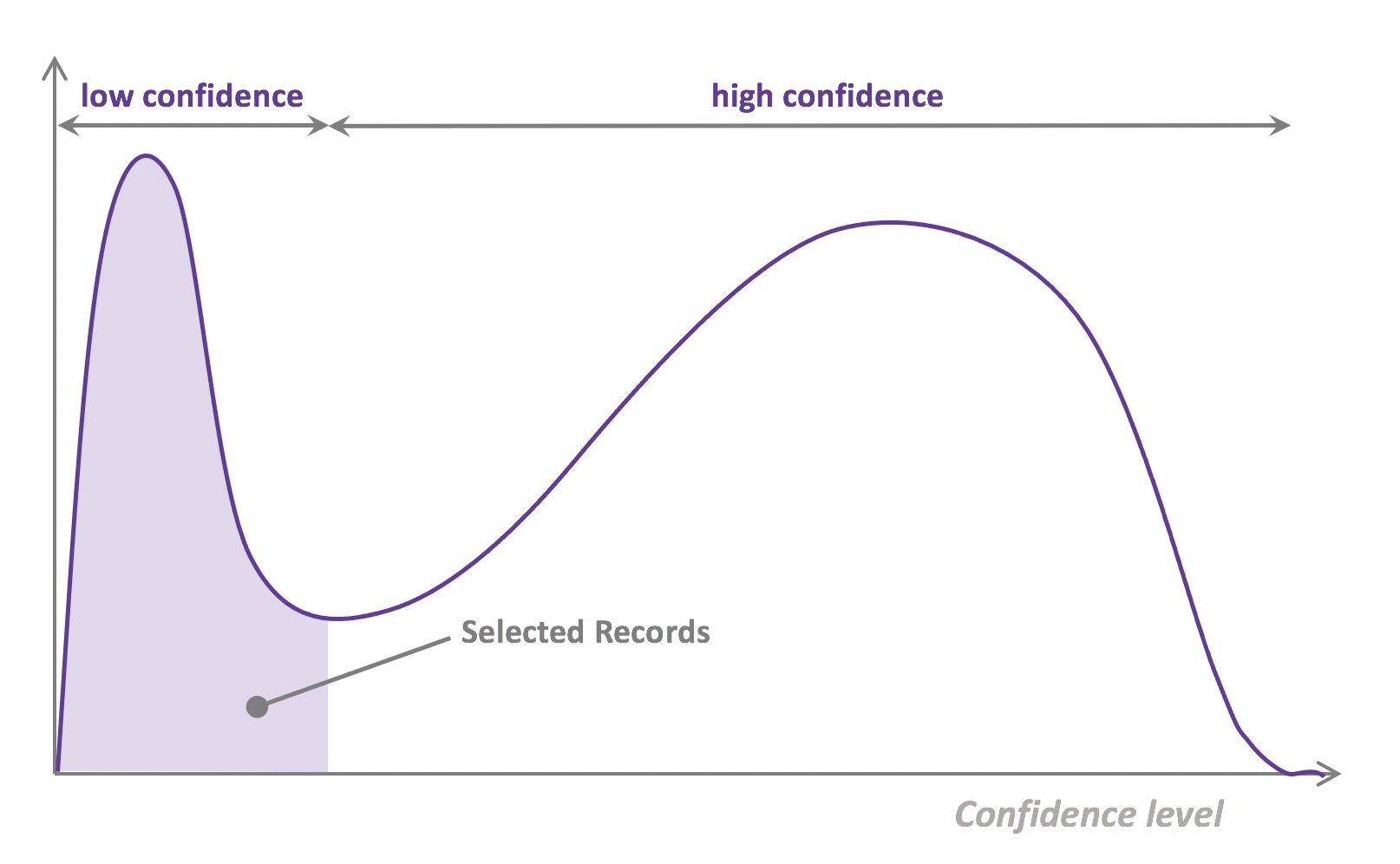
- The easiest and most common querying strategy used for selecting the next batch of useful data consists of picking the records with the lowest confidence level; this is called the least-confidence querying strategy, which is one of many possible querying strategies. (Technically, those querying strategies are usually brute-force, arbitrary algorithms which can be replaced by actual ML models trained on metadata generated during the training and inference phases for more sophistication).
- Thus, the most important criterion is selecting samples with maximum prediction uncertainty. You can use the model’s prediction confidence to ascertain uncertain samples. Entropy is another way to measure such uncertainty. Another criterion could be diversity of the new sample with respect to exiting training data. You could also select samples close to labeled samples in the training data with poor performance. Another option could be selecting samples from regions of the feature space where better performance is desired. You could combine all the strategies in your active learning decision making process.
- The training is an iterative process. With active learning you select new sample to label, label it and retrain the model. Adding one labeled sample at a time and retraining the model could be expensive. There are techniques to select a batch of samples to label. For deep learning the most popular active learning technique is entropy with is Monte Carlo dropout for prediction probability.
- The process of deciding the samples to label could also be implemented with Multi Arm Bandit. The reward function could be defined in terms of prediction uncertainty, diversity, etc.
- Let’s go deeper and explain why the vanilla form of Active Learning, “uncertainty-based”/”least-confidence” Active Learning, actually perform poorly via real-life datasets:
- Let’s take the example of a binary classification model identifying toxic content in tweets, and let’s say we have 100,000 tweets as our dataset.
- Here is how uncertainty-based AL would work:
- We pick 1,000 (or another number, depending on how we tune the process) records - at that stage, randomly.
- We annotate that data as toxic / not-toxic.
- We train our model with it and get a (not-so-good) model.
- We use the model to infer the remaining 99,000 (unlabeled) records.
- We don’t have ground truth for those 99,000, so we can’t select which records are incorrectly predicted, but we can use metadata, such as the confidence level, as a proxy to detect bad predictions. With least confidence Active Learning, we would pick the 1,000 records predicted with the lowest confidence level as our next batch.
- Go to (2) and repeat the same steps, until we’re happy with the model.
- What we did here, is assume that confidence was a good proxy for usefulness, because it is assumed that low confidence records are the hardest for the model to learn, and hence that the model needs to see them to learn more efficiently.
- Let’s consider a scenario where it is not. Assume now that this training data is not clean, and 5% of the data is actually in Spanish. If the model (and the majority of the data) was meant to be for English, then chances are, the Spanish tweets will be inferred with a low confidence: you will actually pollute the dataset with data that doesn’t belong there. In other words, low confidence can happen for a variety of different reasons. That’s what happens when you do active learning with messy data.
- To resolve this, one solution is to stop using confidence level alone: confidence levels are just one meta-feature to evaluate usefulness.
- In a nutshell, active learning is an incremental semi-supervised learning paradigm where training data is selected incrementally and the model is sequentially retrained (loop after loop), until either the model reaches a specific performance or labeling budget is exhausted.
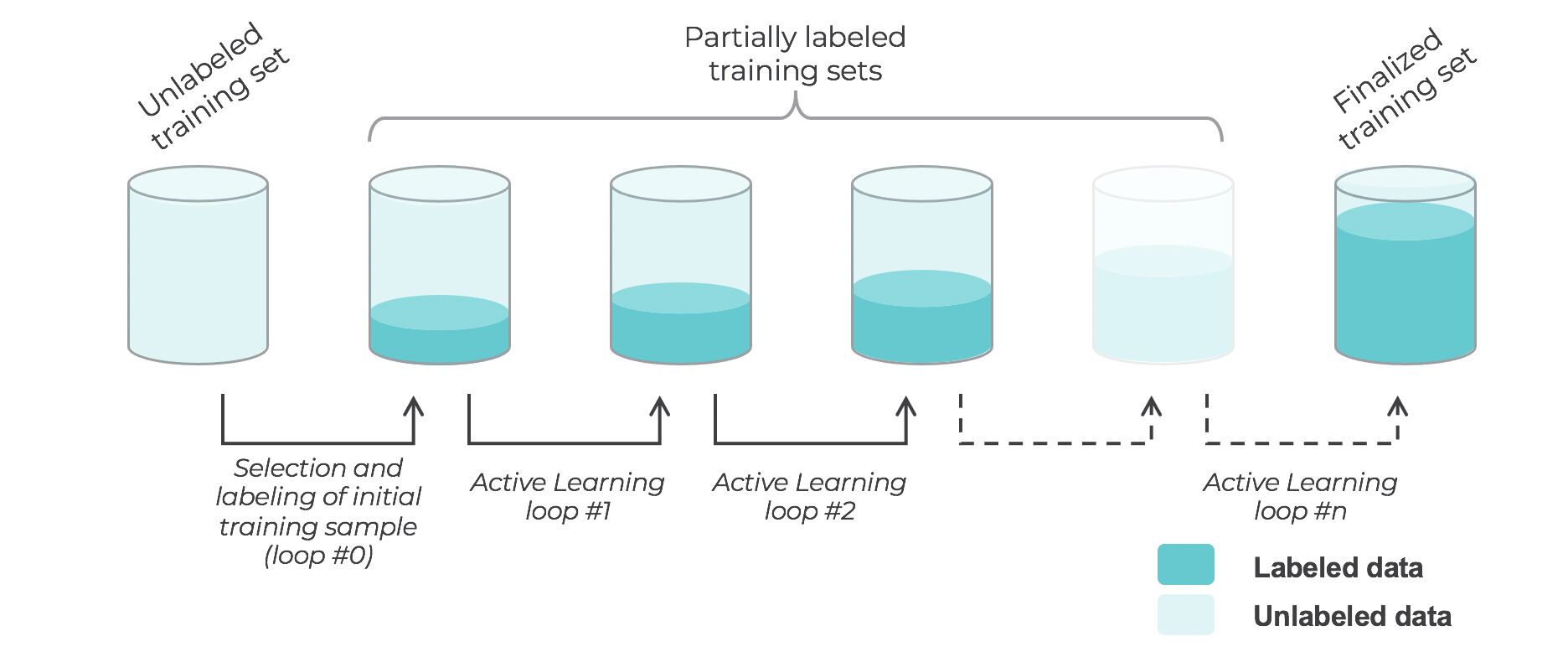
What are the Types of Active Learning?
- There are many different “flavors” of active learning, but did you know that active learning could be broken down into two main categories, “streaming active learning”, and “pooling (batch) active learning”?
- Pooling Active Learning, is when all records available for training data have to be evaluated before a decision can be made about the ones to keep. For example, if your querying strategy is least-confidence, you goal is to select the N records that were predicted with the lowest confidence level in the previous loop, which means all records have to be ranked accordingly to their confidence level. Pooling Active Learning hence requires more compute resources for inference (the entire remainder of the dataset, at each loop, needs to be inferred), but provides a better control of loop sizes and the process as a whole.
- Streaming Active Learning, is when a decision is made “on the fly”, record by record. If your selection strategy was to select all records predicted with a confidence level lower than X% for the previous loop, you’d be doing Streaming AL. This technique obviously requires less compute, and can be used in combination with Online Learning, but it comes with a huge risk: there is no guarantee regarding the amount of data that will be selected. Set the threshold too low, and you won’t select any data for the next loop. Set the threshold too high, and all the remaining data gets selected, and you lose the benefit of AL.
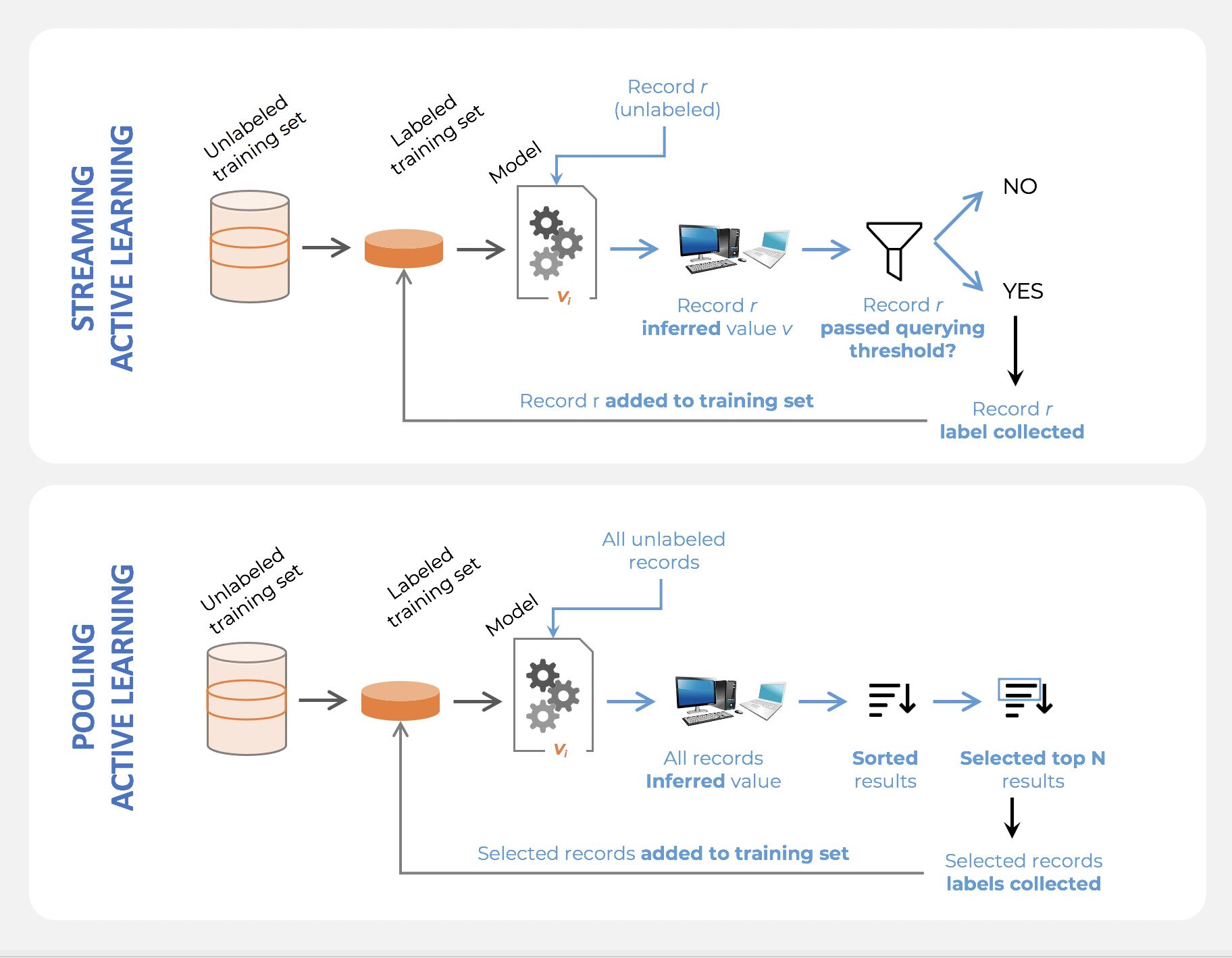
What is the Difference Between Online Learning and Active Learning?
- Online learning is essentially the concept of training a machine learning model on streaming data. In that case, data arrives little-by-little, sequentially, and the model is updated as opposed to be trained entirely from scratch.
- Active learning also consists in training a model sequentially, but the difference is that the training dataset is already fully available. Active learning simply selects small samples of data incrementally; the model is either retrained with the totality of selected records at a given point in time, or updated with the newly selected data.
- Online learning is required when models are to be trained at the point of collection (e.g, on the edge of a device), but active learning, just like supervised learning, usually involves the model being trained offline.
Why is Active Learning Not Frequently Used with Deep Learning?
-
Active Learning was relatively popular among ML scientists during the pre-Deep Learning era, and somehow fell out of favor afterwards.
-
The reason why is actually relatively simple: Active Learning usually doesn’t work as well with Deep Learning Models (at least the most common querying strategies don’t). So people gave up on Deep Active Learning pretty quickly. The two most important reasons are the following:
- The least-confidence, by far the most popular querying strategy, requires the computation of a confidence score. However, the softmax technique which most ML scientists rely on, is relatively unreliable (see this article for details to learn about a better way to compute confidence: https://arxiv.org/pdf/1706.04599.pdf)
- Active learning, as a process, is actually meant to “grow” a better dataset dynamically. At each loop, more records are selected, which means the same model is retrained with incrementally larger data. However, many hyperparameters in neural nets are very sensitive to the amount of data used. For example, a certain number of epochs might lead to overfitting with early loops and underfitting later on. The proper way of doing Deep Active Learning would be to do hyperparameter tuning dynamically, which is rarely done.
Code
DeepAL+: Deep Active Learning Toolkit MLSysOps/Active-Learning-as-a-Service